rust实现TOTP算法(Base32加密)
公司用来进行二次验证登陆的方式是TOTP,全称是_Time-based One-Time Password algorithm_。维基百科上对与TOTP的说明的十分详细:基于时间的一次性密码算法 从这里我们可以找到我们需要实现一个totp可能需要用到的要素:epoch,time step,密钥,加密哈希算法等。还有实现_totp_的基本原理。事实上对比一些别的实现,我们也可以知道中文维基上的有错误之处。
这一次我将记录我实现totp算法的过程以及遇到的坑。
这一次实现的代码可以在我的Github中找到。Github: totp
Base32实现
我们从分析TOTP的密钥开始,去实现一个TOTP算法。拿到一串密钥,它一般可能是长这个样子的:XW7HPZJ2L3AMPWQN。你应该想这是一串密钥,它经过什么处理呢。熟悉密码学的你可能一眼就看出来这串密钥经过怎么样的编码处理,这串密钥应该是经过Base32编码。不过看不出来也没关系,去网络上搜一搜我们也知道一般情况下,totp算法鼓励密钥以Base32编码展示。
这个时候我们应该去找Base32编码解码的crate了。我碰巧知道一个较为成熟的rust库data-encoding,你可以去这里看看,也许你想要它。但这一次,我决定自己来写Base32解码。
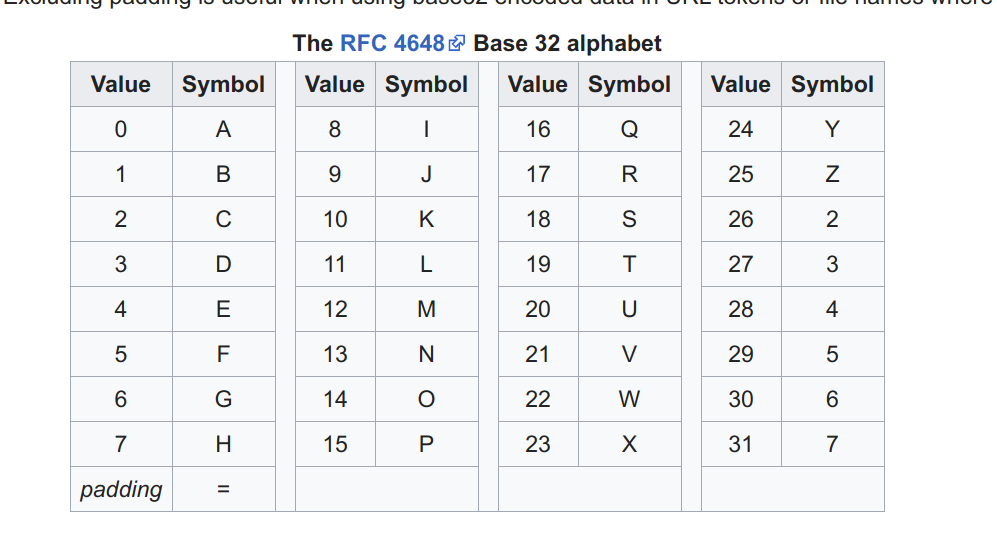
Base32 alphabet和原理
查阅wiki以及网上搜罗来我们知道Base32有以下这样一个对照表,这里面出现的字母不正是我们的密钥XW7HPZJ2L3AMPWQN出现的所有字母嘛。对照着将这些字母写下来:
[23, 22, 31, 7, 15, 25, 9, 26, 11, 27, 0, 12, 15, 22, 16, 13]
Base32编码有以下几个要点:
- 将原始数据的二进制形式拆成5位一组
- 再将5位一组的数据的十进制值写出来
- 以这些十进制值对照这个表,选择对应的字母
所以我们解码的过程也就简单了:
- 根据表格将对应十进制值写出
- 再将这些十进制值展示位5位的二进制
- 连接这些二进制即可获得原始数据
代码
很可惜,在rust中我没能找到一个合适的位操作方式将十进制展现为5位的二进制并连接起来,所以在这里我们使用字符串以及rust的format!宏,虽然这会有一定的开销,但我们奔着实现原理来,先忽略这些细枝末节。
format!宏+Binarytrait,可以完成位数补足以及二进制展示的目的。比如这里format!("{:05b}", x),表示以5位二进制展示x值,并对不足用0补足。- 对于合并后的bits,我使用
Vec的chunks方法,分隔成8位一组写入一个全新的Vec<u8>当作原始数据返回,即是编码前的数据。 - 由于整个过程中出现了多次字符串和u8之间的转换,以及可能的非正常base32字母,我将他们封装到一个错误类型
ParseError中了 - 字母表和十进制值之间的映射采用了粗暴了ASCII值的加减操作完成
pub fn base32_to_secret(s: &str) -> Result<Vec<u8>, ParseError> {
let mut all_bits = String::new();
for b in s.bytes() {
let x:u8;
if b >= 65 && b<=90 {
x = b-65;
} else if b >= 50 && b<= 55 {
x = b-50+26;
} else {
return Err(ParseError::InvalidBase32Char);
}
let bits = format!("{:05b}", x);
all_bits.push_str(&bits);
}
let all_chars:Vec<char> = all_bits.chars().collect();
let all_u8:Result<Vec<u8>, _> = all_chars.chunks(8).map(|chunk| {
let s:String = chunk.iter().collect();
u8::from_str_radix(&s, 2)
}).collect();
Ok(all_u8?)
}
如果你有更好的操作方式,请你评论告诉我。
totp实现
先前说到,totp实现有几个要素:epoch,time step,哈希加密算法,密钥等。但我们可以从一个default开始,因为万事总有一个default,维基百科上说,默认time step是30s,默认的哈希加密方式为_SHA1_,我还知道很多二次验证默认的epoch就是UNIX_TIME_EPOCH,即从1970年0点0分开始计算的秒数。
那么我们可以开始写这样一个算法了。
wiki上是这么说的:

原理
原理可以阐述为:
- 从开始时间到当前时间的time step 个数就是C
- 使用HMAC计算以C为消息,密钥为密钥的哈希值H
- 取得到的哈希值H最后的4位为offset
- 从offset字节开始在H中取4个字节,并抛弃最高位,将剩余的位存为u32 I
- 取十进制I中后6个数作为密码
注意:这里阐述的原理已经和wiki上是不一样的了,我们取的不是4个位而是4个字节,将4个位存为u32本身就不太合理了。
代码
pub fn get_code(secret: &str) -> Result<u32, ParseError>{
let time_count:i64 = ((Utc::now().timestamp_millis() as f64/1000.0 + 0.5)/30) as i64;
let key = base32_to_secret(secret)?;
let mut hmac = Hmac::new(Sha1::new(), &key);
hmac.input(&time_count.to_be_bytes());
let result = hmac.result();
let code = result.code().to_vec()
let offset = (code.last().unwrap() & 0x0f) as usize;
let mut otp = (&code[offset..offset+4]).to_vec();
otp[0] = otp[0] & 0x7f;
let hex:String = otp.iter().map(|chunk| {
format!("{:02X}", chunk)
}).collect();
Ok(u32::from_str_radix(&hex, 16)?%1000000)
}
以上的代码就是一个default的TOTP算法的实现。我们使用了rust-crypto crate(rust-crypto),按照wiki上的介绍,我使用了hmac算法,使用我们的密钥作为key,使用默认的30秒time step以及unix epoch起始计算出来的time count作为消息。使用SHA1作为hash加密算法后,对取得的哈希值我们取最后的四个位作为offset,然后从offset开始取四个字节,将取得的结果转换为十进制,并取后六位作为我们最终的密码。
实际中我们就是拿这样一个六位的密码进行相应的校验的。
改进
这个时候我们应该是已经达到我们自己的目的了,我们可以通过,更改加密算法,time step以及时间起点等来获得我们想要的不同情形下的totp算法实现。但是实际上我们却不能总是靠改代码来实现,我们可以根据哪些是可变的量做相应的更改,将这个totp算法实现变成一个模块化可以复用的crate,甚至可以将它上传到crates.io中。
模块化
根据wiki我做了一些评估,我觉得:
- base32编码是可选的
- time step,start time以及加密方式是可以变更的。
- secret 是可变的
所以如果要实现一个模块化的totp算法,那么base32编码不应该在算法计算过程中,但是可以写一个功能性的关联函数来达到编码。至于剩下的一些可变的量,我们可以创建一个TOTP结构体,像这样:
pub struct TOTP {
secret: String,
time_step: f64,
epoch_start: i64,
encryption: Encryption,
}
其中Encryption可以是一个枚举。
设计好这个结构体,我们可以评估以下应包含哪些方法:
new传入各种字段,创建一个TOTP实例default传入secret创建一个默认设置的TOTP实例get_code核心方法,获得六位数的结果,包含我们的计算过程
当然具体这个模块实现下来也不是轻而易举的,我们需要考虑诸如入参出参类型和错误处理等。 具体实现请移步github:rust totp
优化
当然另一个改进的方向就是性能的优化,其中一个重要的点就是,我在这个过程中许多的位操作都是使用字符串来完成的,可以有一个直接操作位的方式来达到这个目的,使用unsafe代码当然应当可以达到这个目的,那么有没有不用unsafe的方式,这个是有待商榷的。
还有一个自然而然就是文档了,文档应当是这个模块的重要组成部分。